|
Wei Li (李巍) I am Wei Li, a second-year Ph.D. student in the School of Computer Science and Technology, Harbin Institute of Technology (Shenzhen), advised by Prof. Rui Shao. My research interests include Computer Vision, Vision-Language Models, and Vision-Language–Action Models. |

|
Selected Publications |
|
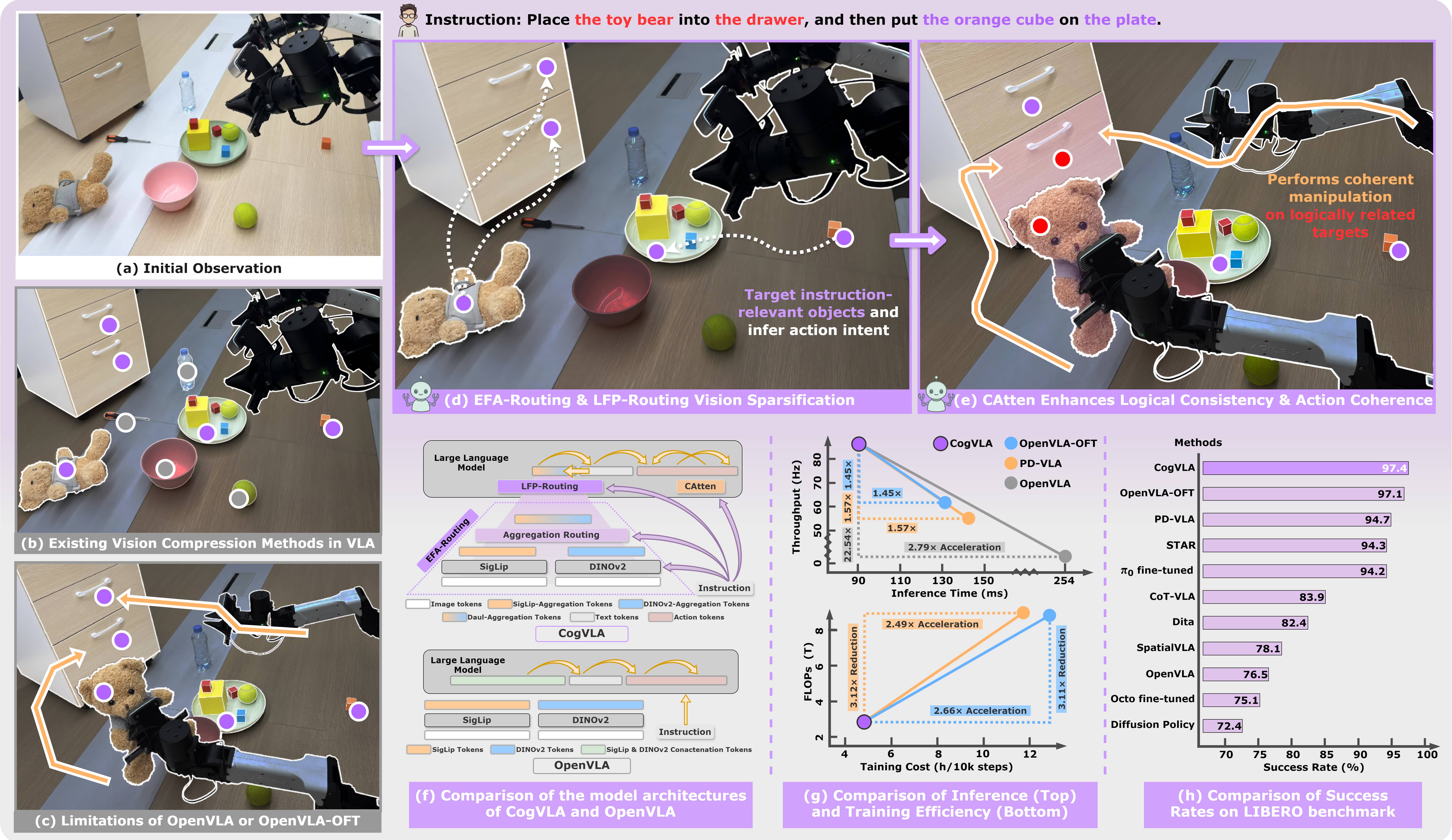
CogVLA: Cognition-Aligned Vision-Language-Action Models via Instruction-Driven Routing & Sparsification
Wei Li, Renshan Zhang, Rui Shao, Jie He, Liqiang Nie NeurIPS 2025 arXiv / github We presented CogVLA, a cognition-aligned and instruction-driven Vision-Language-Action framework designed to address the computational inefficiencies and semantic fragmentation in existing VLA models |
|
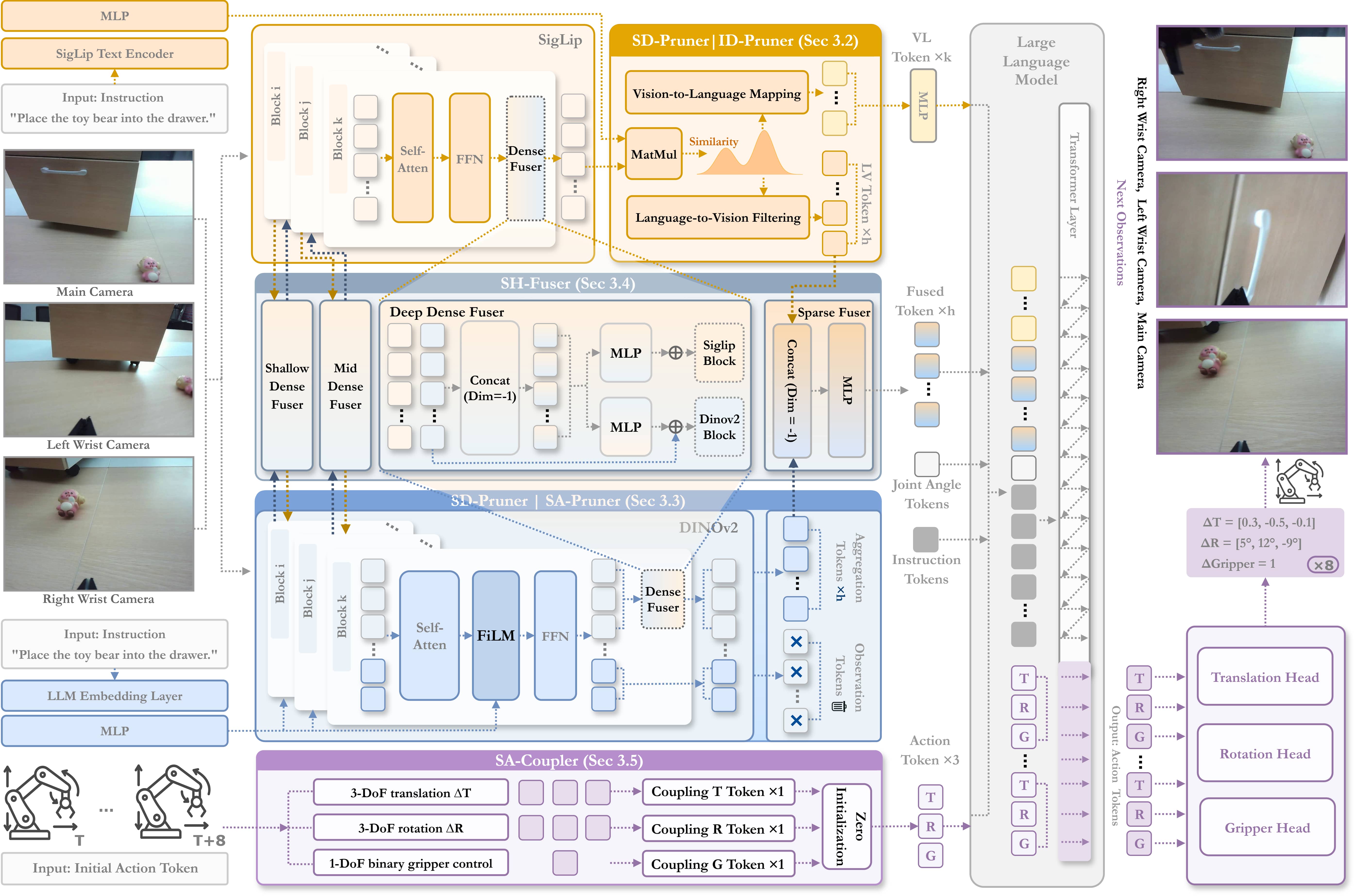
SemanticVLA: Semantic-Aligned Sparsification and Enhancement for Efficient Robotic Manipulation
Wei Li, Renshan Zhang, Rui Shao, Zhijian Fang, Kaiwen Zhou, Zhuotao Tian, Liqiang Nie AAAI 2026, Oral arXiv / github SemanticVLA formulates vision–language–action learning as a semantic selection–fusion–action coupling process, providing an interpretable and efficient pathway from multimodal perception to robotic action. |
|
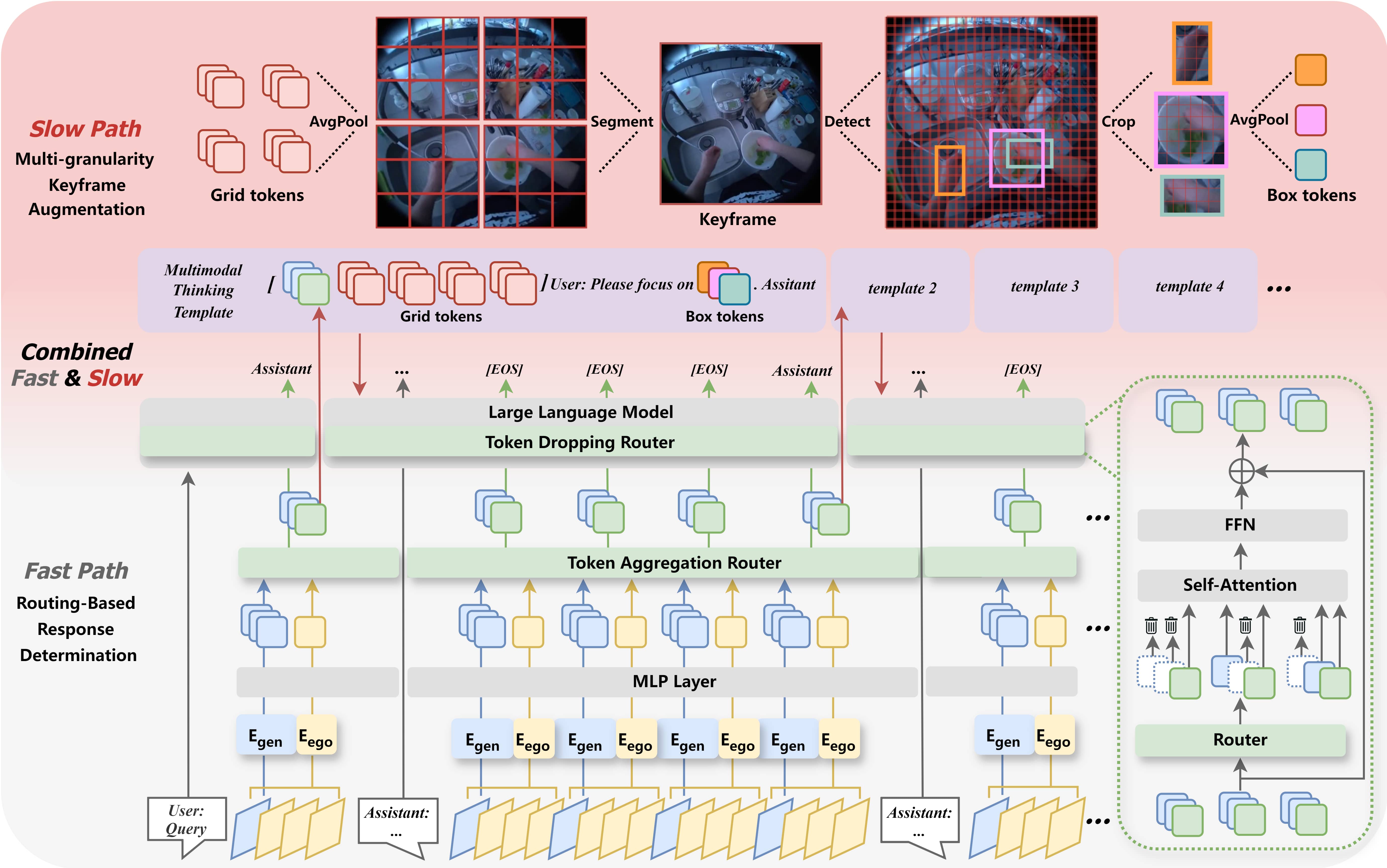
LION-FS: Fast & Slow Video-Language Thinker as Online Video Assistant
Wei Li, Bing Hu, Rui Shao, Leyang Shen, Liqiang Nie CVPR 2025 arXiv / github LION-FS adopts a two-stage optimization strategy: 1) Fast Path: Routing-Based Response Determination evaluates frame-by-frame whether an immediate response is necessary. 2) Slow Path: Multi-granularity Keyframe Augmentation optimizes keyframes during response generation. |
|
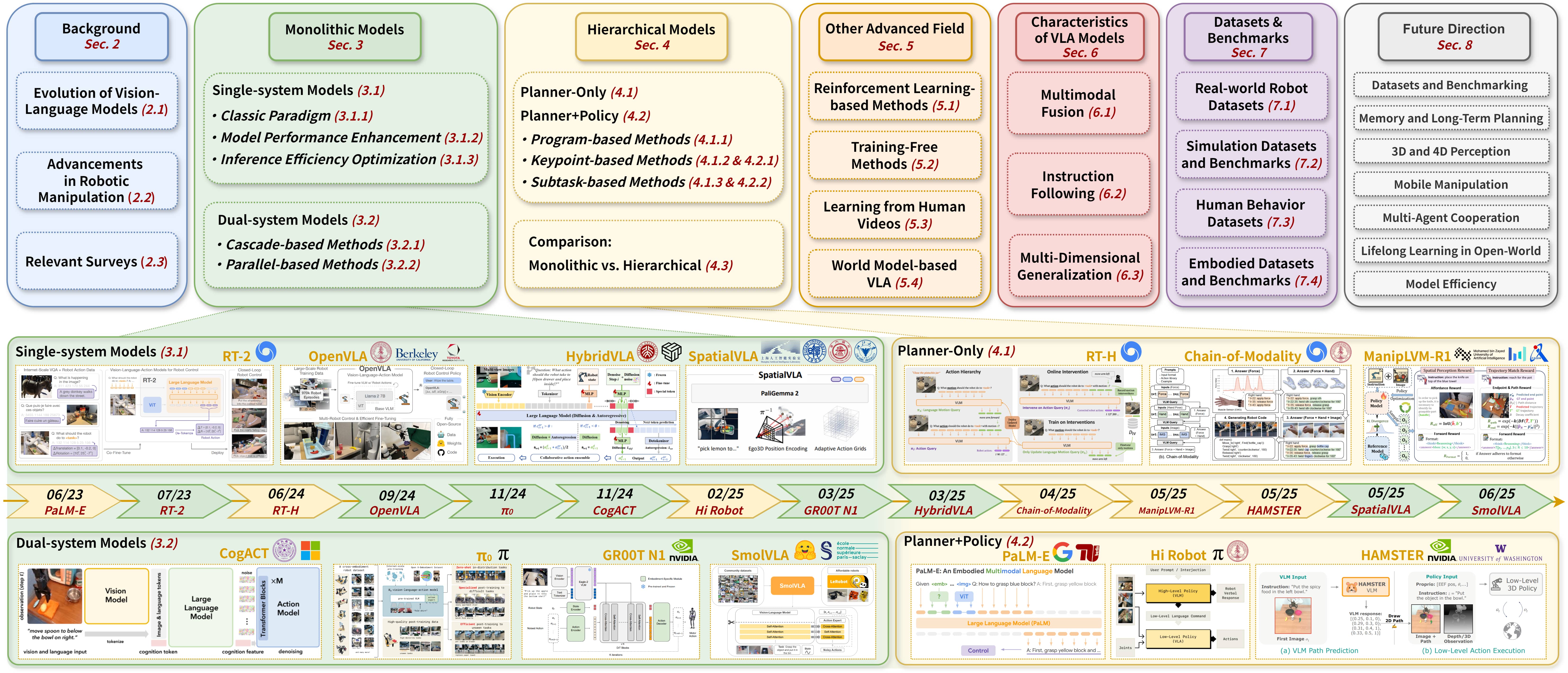
Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
Rui Shao, Wei Li, Lingsen Zhang, Renshan Zhang, Zhiyang Liu, Ran Chen, Liqiang Nie arXiv / github This survey provides the first systematic, taxonomy-oriented review of large VLM-based VLA models for robotic manipulation. |
|
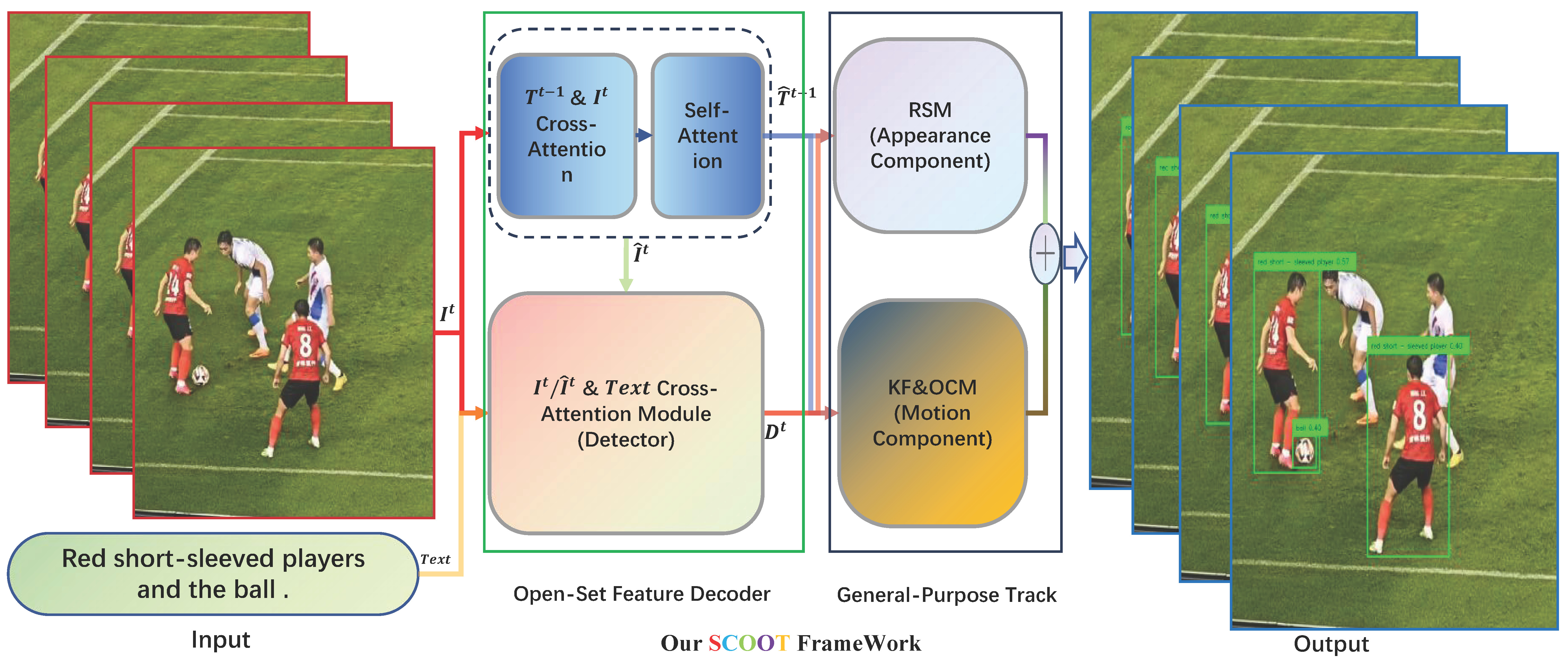
SCOOT: Self-supervised Centric Open-set Object Tracking
Wei Li, Weiliang Meng, Bowen Li, Jiguang Zhang, Xiaopeng Zhang SIGGRAPH Asia 2023, Poster page SCOOT unifies self-supervised appearance learning, textual-visual feature fusion, and reconstruction-driven association to advance open-set object tracking. |
Education & Experience |
|
•
Harbin Institute of Technology (Shenzhen)
2024.09 - Present
Ph.D. in Computer Science and Technology, School of Computer Science and Technology
Advised by Rui Shao |
|
•
University of Chinese Academy of Sciences
2021.09 - 2024.06
M.S. in Artificial Intelligence, Institute of Automation, Chinese Academy of Sciences
Advised by Weiliang Meng |
|
•
Jilin University
2017.09 - 2021.06
B.S. in Electronic Information, School of Communication Engineering
|
Academic Services |
| •Conference Reviewer: CVPR, ICML and ECCV. |
|
Last updated: January 2026 Template by Jon Barron. |